Just a few of the apps we have made with the app template. Photo by Emily Bogle.
On the NPR Visuals Team, we make a point to open source and publish as much of the code we write as we can. That includes open sourcing code like the app template, which we use every day to build the individual projects we make as a team.
However, we tend to optimize for ourselves rather than for the public, which means it can be a little more difficult for someone outside of our team to setup the app template. For this reason, I will walk through how to set up the app template for yourself if you are not a developer on our team. If you are unfamiliar with the app template, read more about it here.
In this post, you will learn how to:
- Ensure your development environment will work with the app template.
- Set up a fork of the app template with your defaults.
- Clone and bootstrap the app template for an individual project.
- Deploy app template projects.
- Customize the app template for your use and remove NPR branding.
Prerequisites
Our app template relies on a UNIX-based development environment and working knowledge of the command line. We have a Python and Node-based stack. Thus, if you are new to all of this, you should probably read our development environment blog post first and make sure your environment matches ours. Namely, you should have Python 2.7 and the latest version of Node installed.
Also, all of our projects are deployed from the template to Amazon S3. You should have three buckets configured: one for production, one for staging and one for synchronizing large media assets (like images) across computers. For example, we use apps.npr.org, stage-apps.npr.org and assets.apps.npr.org for our three buckets, respectively.
Cloning the template
All of our projects start and end in version control, so the first thing to do for your project is to fork our app template so you have a place for all of your defaults when you use the app template for more projects. This is going to be the place where all of your app template projects begin. When you want to start a new project, you clone your fork of the app template.
Once that is done, clone your fork to your local machine so we can start changing some defaults.
git clone git@github.com:$YOUR_GITHUB_USERNAME/app-template.git
Set up your development environment
Hopefully, you’ve already checked to make sure your development stack matches ours. Next, we’re going to create a virtual environment for the app template and install the Python and Node requirements. Use the following commands:
mkvirtualenv app-template
pip install -r requirements.txt
npm install
Environment variables
You will also need a few environment variables established so that the entire stack works.
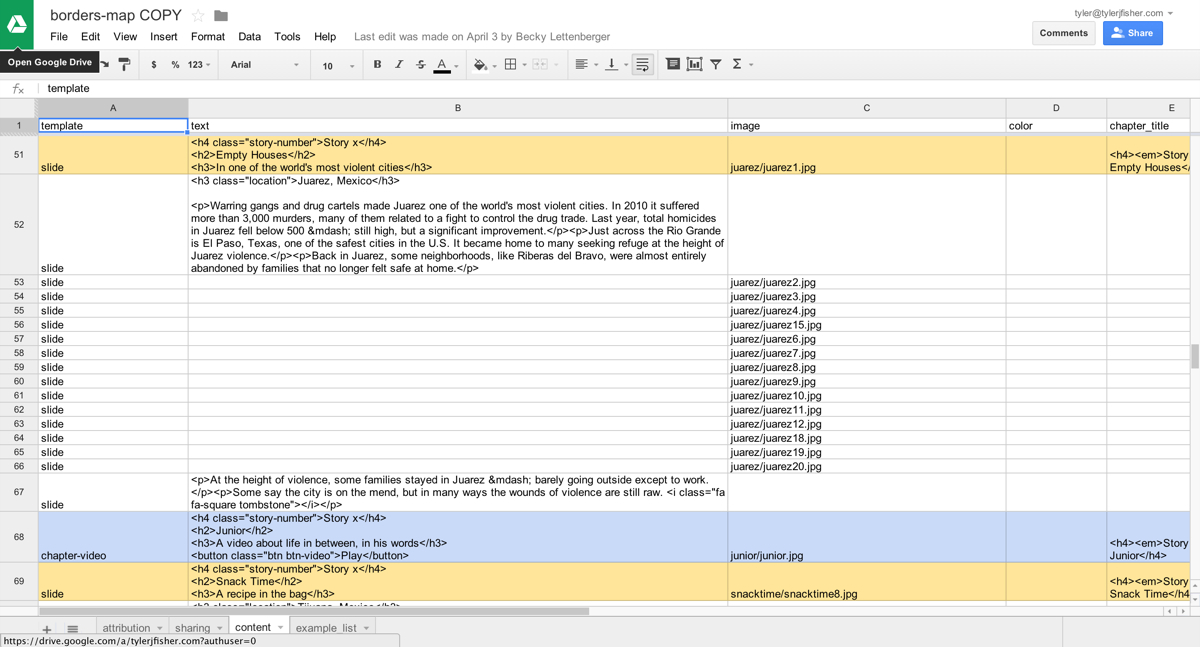
In order to use Google Spreadsheets with copytext from within the app template, you will need to store a Google username and password in your ’.bash_profile’ (or comparable file for other shells like zsh).
export APPS_GOOGLE_EMAIL="youremail@gmail.com"
export APPS_GOOGLE_PASS="ih0pey0urpassw0rdisn0tpassword"
When you create spreadsheets for your projects, ensure the Google account stored in your environment can access the spreadsheet.
For deployment to Amazon S3, you will need your AWS Access Key ID and Secret stored as environment variables as well:
export AWS_ACCESS_KEY_ID="$AWSKEY"
export AWS_SECRET_ACCESS_KEY="$AWSSECRET"
After you have set these variables, open a new terminal session so that these variables are a part of your environment.
Setting your defaults
With your development environment and environment variables set, we can start hacking on the template.
All of the configuration you will need to change lives in ‘app_config.py’. Open that file in your text editor of choice. We will edit a few of the NPR-specific defaults in this file.
Change the following variables:
GITHUB_USERNAME: Change this to your (or your news org’s) Github username.PRODUCTION_S3_BUCKETS, STAGING_S3_BUCKETS and ASSETS_S3_BUCKET: You should change these dictionaries to the three buckets you have setup for this purpose. We also have a backup production bucket in case apps.npr.org goes down for any reason. Be sure to note the region of each S3 bucket.COPY_GOOGLE_DOC_URL: Technically, the default Google Spreadsheet for our projects is viewable by anyone with the link, but you should make your own and use that as the default spreadsheet for your projects. That way, you can change the default sheet style for your projects. For each individual project, you will want to make a copy of your template post and update the URL in the individual project’s 'app_config.py’.GOOGLE_ANALYTICS: ACCOUNT_ID: We love you, but we don’t want to see the pageviews for your stuff in our analytics. Please change this to you or your news org’s ID.DISQUS_API_KEY: If you want to use Disqus comments, retrieve your public Disqus API key and paste it as the value for this variable.DISQUS_SHORTNAME: We configure different Disqus shortnames for different deployment targets. You can set yours in the configure_targets() function in app_config.py
You will also notice the variables PRODUCTION_SERVERS and STAGING_SERVERS. Our app template is capable of deploying cron jobs and Flask applications to live servers. We do this for apps like our Playgrounds app.
If you are going to use these server-side features, you will want to create a couple EC2 boxes for this purpose. As our defaults show, you can either create a full URL for this box or just use an elastic IP.
Testing your new config
With all of this changed, you should be able to bootstrap a new project, work on it, and deploy it with the entire pipeline working. Let’s try it!
Testing cloning and bootstrapping
First, make sure you have pushed all of the changes you just made back to Github. Then, make a test repository for a new app template project on Github. Take note of what you call this repository.
Clone your fork of the app template once again. This is how you will begin all individual app template projects. This time, we’re going to specify that the clone is created in a folder with the name of the repository you just created. For example, if you made a repository called 'my-new-awesome-project’, your clone command would look like this:
git clone git@github.com:$YOUR_GITHUB_USERNAME/app-template.git my-new-awesome-project
Next, run the following commands:
cd my-new-awesome-project
mkvirtualenv my-new-awesome-project
pip install -r requirements.txt
npm install
fab bootstrap
If you go back to the my-new-awesome-project you created, you should see an initial commit that puts the app template in this repository. If this worked, you have made all the changes necessary for bootstrapping new app template projects.
Testing the local Flask app
In the project’s root directory in the terminal, run ./app.py. Then, open your web browser and visit http://localhost:8000
You should see a web page (albeit one with NPR branding all over it… we’ll get there). If you see an error, something went wrong.
Testing deployment
Finally, let’s test deployment. Run fab staging master deploy. Visit YOUR-S3-STAGING-BUCKET.com/my-new-awesome-project to see if deployment worked properly. You should see the same page you saw when you ran the local Flask server.
If everything we just tested worked, then you are ready to start using the app template for all of your static site needs. Happy hacking!
Below, I will get into some finer details about how to turn off certain features and get rid of more NPR-specific defaults
Customizing and Ripping Out Features
Chances are, if you are using our app template, you don’t want to use all of our template. We’re fully aware that some of ways we do things are esoteric and may not work for everyone. Other things are our standard defaults, but won’t work for your projects. Here are some things you will probably want to change.
Fonts
We automatically include the NPR-licensed Gotham web font. You can’t use this. Sorry. If you go to templates/_fonts.html, you can point to your own hosted webfont CSS files, or alternatively, remove the template include from templates/_base.html to turn off the webfont feature entirely.
Ads
We have a rig to serve NPR ads on some of our apps. We’re pretty sure you won’t want NPR ads on your stuff. To remove the ads, remove two files from the repo: www/js/ads.js and less/adhesion.less. Then, in templates/_base.html, remove the call to js/ads.js and in less/app.less, remove the import statement that imports the adhesion.less file.
Finally, in app_config.py, you should remove the NPR_DFP dict, as it will now be unnecessary.
Front-end defaults
We have a base template setup so that we can see that all of the template is working easily. You will probably want something similar, but you will want to strip out the NPR header/footer and all the branding. You can do that by editing the various templates inside the templates folder, especially _base.html and index.html and editing app.less.
Sharing tools and comments
All of our apps come with a common share panel and comments form. We use Disqus for comments and integrate with Facebook and Twitter. This may or may not work for you. Should you want to remove all of these features, remove the following files:
data/featured.json fabfile/data.pyless/comments.less less/comments_full.less less/share-modal.lesstemplates/_disqus.html templates/_featured_facebook_post.htmltemplates/_featured_tweet.htmltemplates/_share_modal.htmlwww/js/comments.js
Be sure to check for where these files are included in the HTML and less templates as well.
Google Spreadsheets
To turn off the dependency on Google Spreadsheets, simply set the variable COPY_GOOGLE_DOC_URL in app_config.py to None.
Note that many of the default templates rely on a COPY object that is retrieved from a local .xlsx file stored in the data directory. That file path is set by the COPY_PATH variable in app_config.py.
If you want to factor out all spreadsheet functionality, this will take a lot more work. You will need to completely remove the dependency on copytext throughout the app template.
This seems like a lot. Why should I do this?
Our app template is customized for our needs. It has a great many NPR-specific defaults. If you want to use the app template for projects outside of NPR, it takes a good amount of customization to truly decouple the template from NPR defaults.
But we think the payoff would be worth it for any news organization. Having a baseline template with sensible defaults makes all of your future projects faster, and you can spend more time focusing on the development of your individual project. We spend so much time working on our template up front because we like to spend as much time as we can working on the specifics of an individual project, rather than building the 90% of every website that is the same. The app template allows us to work at a quick pace, working on weekly sprints and turning around projects in a week or two.
If you work for a news organization looking to turn around web projects quickly, you need a place to start every time. Instead of making broad, templated design decisions that compromise the functionality and purpose of a project, use our template to handle the boring stuff and make more amazing things.
















 (This is just a screenshot. You can see the animated version in the
(This is just a screenshot. You can see the animated version in the 

{kind=link}
{kind=link}